在當今數字化、高效率的商業環境中,專業的通信管理與成本控制軟件已成為企業運營不可或缺的工具。北京市梓博軟件錄音電話計費公司,憑借其深厚的技術積累與行業洞察,推出了一系列功能強大、穩定可靠的軟件產品,旨在幫助企業優化通信流程、精準核算成本并提升管理效能。以下通過產品相冊圖片的視角,為您直觀展示其核心軟件銷售產品的特色與價值。
一、 核心產品概覽
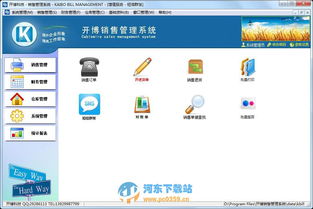
產品相冊的首系列圖片,集中展示了公司旗艦產品——智能錄音電話計費管理系統。從系統架構圖到軟件主界面截圖,圖片清晰呈現了其模塊化設計:通話錄音、實時計費、話單分析、權限管理、報表生成等核心功能一目了然。界面設計簡潔明了,采用商務藍與科技灰為主色調,體現了專業與可靠。圖片特寫突出了其支持多種電話交換機(PBX)接口、海量通話數據快速處理以及數據加密存儲等關鍵技術點。
二、 功能細節與場景應用
接下來的組圖深入展示了軟件的具體功能與應用場景。
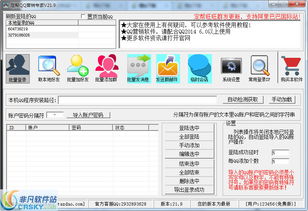
- 高清錄音與檢索:圖片展示了通話錄音的波形圖與列表視圖,支持按時間、號碼、部門等多條件快速檢索與播放,音質清晰,便于事后核查與服務質量監督。
- 靈活計費策略:通過配置界面的截圖,展示了軟件如何自定義計費規則(如分時段、分部門、分項目計費),并能與多種資費套餐無縫對接,幫助企業實現成本精細化分攤。
- 多維數據報表:生成的各類統計圖表(如餅圖、柱狀圖、趨勢圖)圖片,直觀反映了通話時長分布、費用構成、部門使用排行等,為管理決策提供堅實的數據支撐。
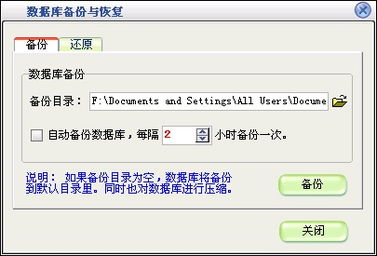
- 安全與權限管理:系統管理后臺的截圖,展示了多級角色權限分配功能,確保不同部門、崗位的員工只能訪問其授權范圍內的數據和功能,保障企業信息安全和運營合規。
三、 技術優勢與兼容性
產品相冊中專門有一組圖片呈現了軟件的技術底層與兼容特性。圖示說明了其采用的B/S(瀏覽器/服務器)或C/S(客戶端/服務器)架構,支持在Windows Server、Linux等多種服務器環境上穩定運行。網絡拓撲圖展示了軟件如何與企業現有的電話系統、辦公OA及ERP系統進行集成,實現數據互通,打破信息孤島。
四、 客戶服務與實施案例
相冊最后部分并非軟件界面,而是寓意性的圖片:如7x24小時技術支持的服務圖標、專業實施團隊的工作場景、以及獲得服務的部分行業客戶(如金融、客服中心、貿易公司等)的標識剪影(已做匿名化處理)。這些圖片傳達出梓博軟件不僅提供產品,更提供全程化的解決方案與持續的服務保障。
透過北京市梓博軟件錄音電話計費公司的產品相冊圖片,我們可以清晰地看到,其軟件銷售的核心在于提供一套集高效錄音、精準計費、智能分析、安全管控于一體的綜合性解決方案。圖片所展現的專業設計、詳盡功能和靈活適配能力,正是其幫助廣大企業客戶提升通信管理效率、降低運營成本、強化內部管控的價值所在。選擇梓博軟件,即是選擇了一種更智能、更經濟、更安心的企業通信管理方式。